Building Rusty Bucket - Part 1
Table of Contents
- Introduction
- Goals
- Non-goals
- Implementation
- Benchmarking
- Continuous Integration
- The Well-Used Bucket (Story)
In this series of blog posts, I’ll chronicle my journey building a pandas-inspired data analysis library in Rust called rustybucket with some name brainstorming power thanks to @functorism. Today, we’ll focus on the core Series data structure and benchmark its performance.
https://github.com/eleijonmarck/rustybucket - ⭐
Introduction
I use pandas extensively in both my professional and personal data analysis work, and I wanted to learn more about Rust by implementing core pieces of pandas’ functionality. My goal for rustybucket is to have a solid subset of pandas’ API implemented in Rust, allowing for exploration of Rust’s performance characteristics and my own learnings along the way.
For part 1, I’m focusing on implementing rustybucket’s Series - a homogenous array of data with an associated index - and benchmarking basic operations on the structure.
Goals
- Learn more about Rust and its ecosystem
- Implement a
Seriesstruct with indexing/slicing - Write benchmarks to measure performance of core
Seriesoperations
Non-goals
- Full
pandasAPI coverage (for now) - DataFrame or other higher-order structures
Implementation
I started by setting up a new Rust library with cargo new rustybucket --lib. Since this is a library and not an executable, we don’t need a main function.
For the Series implementation, I had to decide between using a Vec (owning, resizable array) or a &[T] slice (borrowed slice of elements). Since we may want to concatenate Series together or adjust capacity, Vec seemed like the clearer choice for now. Here’s the current Series struct:
pub struct Series<T> {
name: String,
data: Vec<T>,
}To enable indexing and slicing, I implemented Index and Slice traits for Series.
With the core struct and traits in place, it was time to write some benchmarks! I used the criterion crate to benchmark basic slicing operations on my Series.
use criterion::{criterion_group, criterion_main, Criterion};
fn slice_series(s: &Series<i32>, start: usize, end: usize) {
let _ = &s[start..end];
}
fn criterion_benchmark(c: &mut Criterion) {
let s = Series::new(String::from("example"), (0..1000).collect());
c.bench_function("slice series", |b| b.iter(|| slice_series(&s, 100, 200)));
}
criterion_group!(benches, criterion_benchmark);
criterion_main!(benches);It turns out that criterion cannot be used in conjunction with benchmark-actions and had to abandon the criterion library for doing the nightly builds with #[bench] instead.
#[bench]
fn slice_a_series_of_size_1000(b: &mut Bencher) {
fn slice_series(s: &series::Series<i32>) {
let _ = &s[1..3];
}
b.iter(|| {
let vec = (0..1000).map(|v| v + 1000).collect::<Vec<i32>>();
let s = series::Series::new(String::from("hej"), vec, None);
for _ in 0..1000 {
test::black_box(slice_series(&s)); // spooky black_box 👻
}
});
}Just when I thought I had cleverly outwitted the Rust compiler’s optimizations by benchmarking my slice_series function. Rust discarded the redundant function calls, yielding a benchmark of 0 ns/iter - infinite speed! ♾️
Running this benchmark does however pose a problem as rust has optimization strategies for their compiler to disgard the function calls of slicing the series to only do it once. DAMN you rust toooo smooth. Instead one has to invoke a black_box call on top of the function being tested. The test::black_box function is an identity function that hints to the compiler to be maximally pessimistic about what black_box could do. All together we got out first benchmark test that actually did not have 0 ns/iter but 412 ns/iter, resulting in infinite performance regression 🤣.
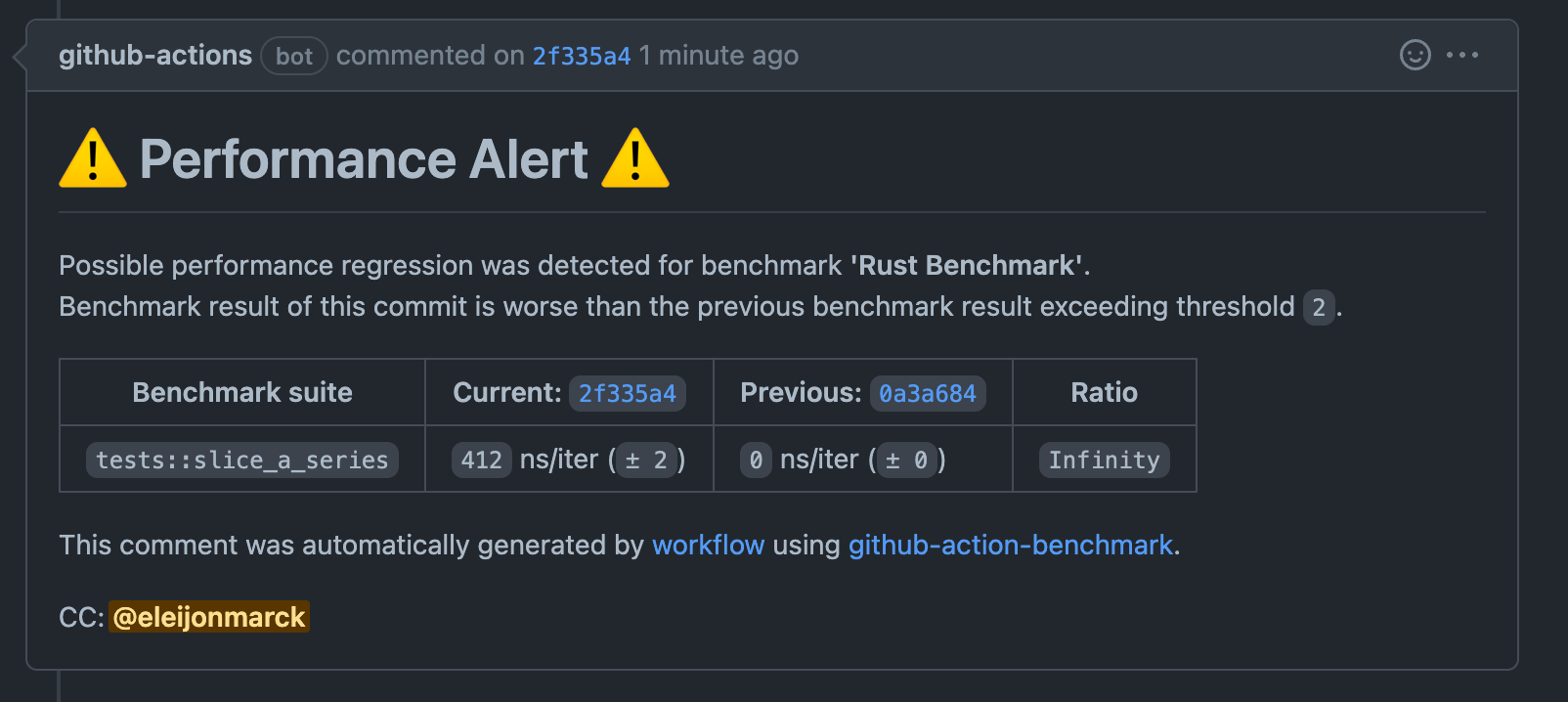
I integrated benchmark testing into the continuous integration (CI) process for my project. This practice of including performance testing as part of CI is known as performance-driven development. Most programming languages and critical systems where performance is crucial (e.g. financial systems) implement this.
This allows all team members to detect performance regressions that may arise from newly added features or bug fixes. We used the benchmark-action GitHub Action, which is specifically designed to run benchmarks in CI. After some trial and error, I got it working by setting up a gh-pages branch in the repository and adding a dev/bench folder on that branch.
Note: It was important to create the gh-pages branch and dev/bench directory because the output.txt file generated by benchmark-action expects those to exist in order to store the benchmark results. (I should have figured that out more quickly!)
Finally, to track performance over time and detect regressions, I set up a GitHub Action to run bench benchmarks on every push and save the results. The benchmark-action made this process straightforward.
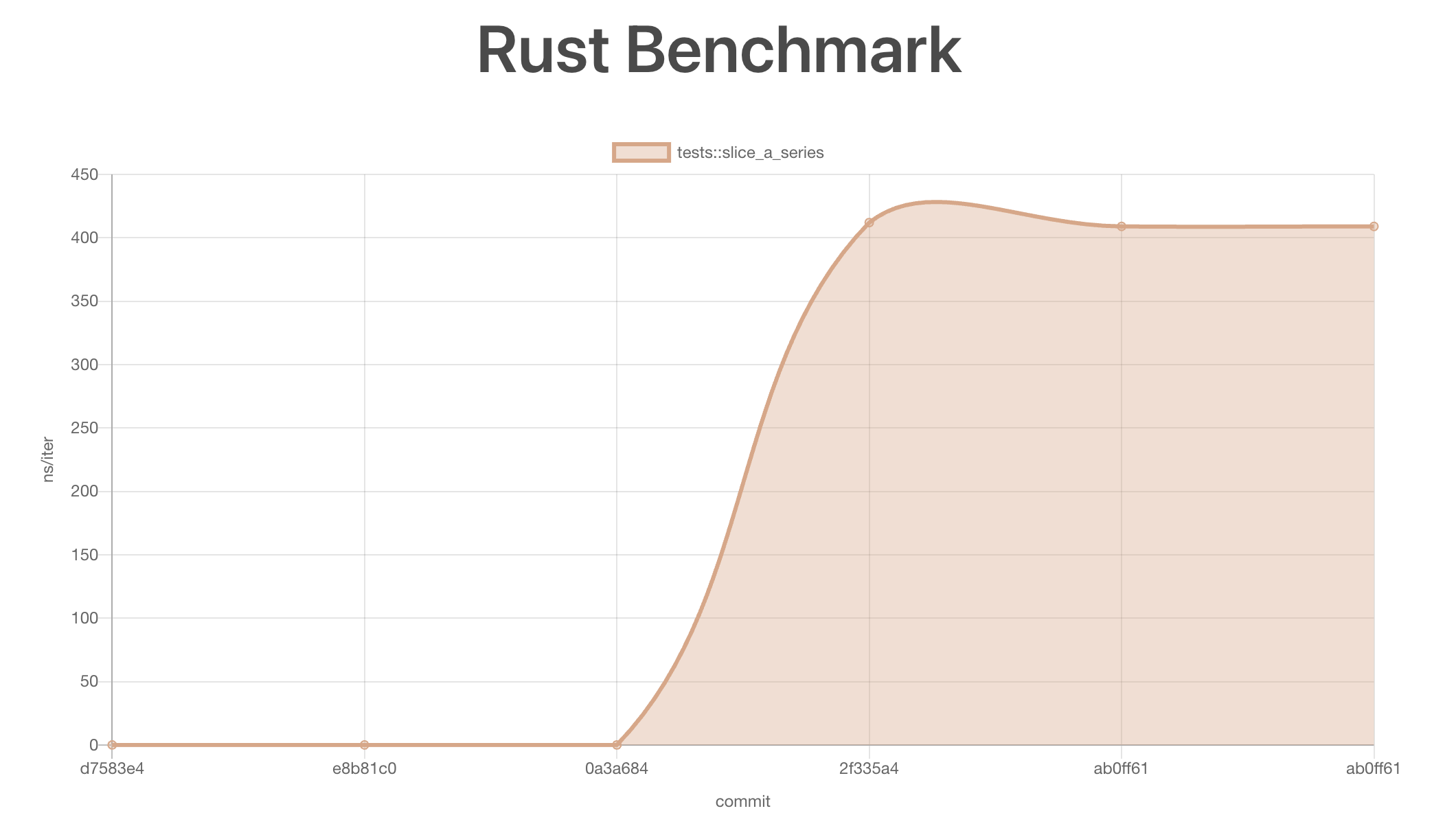
You can see the current benchmark results for rustybucket in the GitHub Pages site for the project, or follow the development @ https://github.com/eleijonmarck/rustybucket.
This is the end of part 1 where we make rustybucket the bucket for data that is rusty better.
The Well-Used Bucket
I would like to share a tale about a bucket that served its purpose admirably, though not without signs of wear and tear.
When it was first acquired, the bucket was gleaming and spotless. However, as time went on and the bucket was utilized repeatedly, it inevitably deteriorated. Its once-shiny exterior became weathered and discolored, coated in a layer of dirt and grime. Rust invaded the metal, leaving orange stains that could not be scrubbed away.
If the bucket is not cleaned regularly, removing the built-up dust and debris and treating the rust before it spreads, it will soon become useless. What was once a perfectly suitable bucket will have transformed into a rusted relic, suitable only for the scrap heap.
